Researchers at the Efi Arazi School of Computer Science at the Interdisciplinary Center Herzliya (IDC Herzliya) in Israel have come up with prototype software that enables even novices to produce a video montage by merely typing in a few sentences describing the kind of production they want.
The system works by interfacing artificial intelligence (AI) software that has been trained to recognize and understand the meaning of keyword search terms with a library of video clips labeled with those search terms. "The tool automatically searches for semantically matching candidate shots from a video repository, and then uses an optimization method to assemble the video montage by cutting and reordering the shots automatically," says Ariel Shamir, dean of the Efi Arazi School of Computer Science.
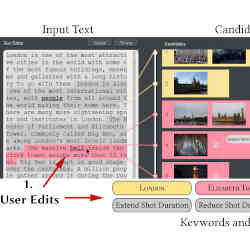
For example, if you type in "London is one of the most attractive cities in the world, with some of the most famous buildings, museums, and galleries, with a long history to go with them," the software will auto-generate a video montage featuring those specific visual elements of London.
Reworking the video is simply a matter of making a change or two to the textual information you type into the software. Add 'concert halls' to the description of London above, for example, and the software will add video footage of London concert halls.
Daniel Cohen-Or, a professor specializing in computer graphics and visualization at Tel Aviv University, counts himself among the impressed. "The software exploits the fact that editing of text is a much simpler task for humans, and cleverly converts text editing to video editing."
Of course, the success of the system hinges in part on being able to anticipate the kinds of descriptive sentences a user might keypunch into the software. The system works extremely well if it's heavily stocked with all sorts of video footage depicting London in all its glory, and is then unleashed on a user who is interested in making London-themed videos. However, the system would be dead in the water if it were equipped with the same London footage, and then asked to create a video montage depicting the neural pathways of the brain.
"Our technique works best on narrative texts with specific themes and assumes that the user wants to create a video, such as how-to videos or travel videos," says Miao Wang, a member of the research team and an assistant professor at China's Beihang University specializing in computer graphics and virtual reality. "We further assume that a video repository related to the subject — containing enough diversity — is available, gathered from online resources or from personal albums."
Video libraries for use by the system must be prepared by carefully annotating each video clip prior to its use, either manually or automatically, according to Wang. Videos drawn from YouTube and similar sites, for example, are automatically tagged by the system with the same keywords a searcher uses to find those videos online, she says.
Moreover, once inside the system, some videos are further tagged by "pre-trained object detectors" in the system software, which look for recognizable objects and then label them accordingly. A video clip of 'Parliament Square' in London, for example, might also be tagged by a pre-trained object detector with the descriptor of 'dog', should a segment of a video clip of that location feature a dog.
Users also can manually annotate videos to be used by the system to ensure specific aspects of the video footage become searchable, according to Wang.
The cost of all that annotation hinges partially on the number of video clips to be added to the video library; more clips require more annotation. But the greatest factor impacting cost is the number of video clips that can be tagged automatically, versus the number of clips that need manual tagging.
"For automatic annotations, the cost is negligible," Wang says. "In our experiments, only one library was manually labeled, and labeling all shots, with a total combined length of three hours and 20 minutes, took the user about 32 minutes."
The system differs from related software experiments in that it enables a video montage to be rendered with much more specificity, according to James Tompkin, an assistant professor at Brown University who specializes in visual computing. "Existing video editing systems to help casual users have often focused on summarization," Tompkin says, "but the techniques didn't have sufficient visual understanding to gain wide adoption."
According to Ivan Laptev, a senior researcher at France's National Institute for Research in Digital Science and Technology, "Video search by text still has major limitations. While finding objects becomes easy, scenes with particular spatial and temporal arrangements are still very hard to search." As a result, Laptev said, "The chance of having an appropriate video that matches an arbitrary text query will be very small — even for very large video databases."
Antoine Miech, a Ph.D. student at France's National Institute for Research in Digital Science who specializes in computer vision, agrees that "The performance of this kind of software really does depend on the training data it was trained on the one hand, and also on the video library you are searching on. If you have both on a very large scale, I believe this type of software can be commercially successful."
Says Wang, "Our method allows researchers to incorporate more advanced visual-semantic matching algorithms," in the future. "This may lead to better performance and wider support of text and video types."
Joe Dysart is an Internet speaker and business consultant based in Manhattan, NY, USA.



Join the Discussion (0)
Become a Member or Sign In to Post a Comment